
数据,宛如一张无边无际的网,将我们紧密地连接在一起。而在这个信息爆炸的时代,数据的产生速度远远超过了我们的想象。作为一名数据分析师,我深知数据的重要性和价值。然而,在处理海量数据的过程中,我们不可避免地会遇到一个问题——数据缓存。
第一章:数据汇集与缓存
在进行数据分析之前,首先需要汇集各种各样的数据源。这些数据源可能来自不同的部门、不同的系统甚至不同的国家。然而,由于网络传输速度和稳定性等因素的限制,无法实时获取所有需要的数据。为了解决这个问题,我们需要进行数据缓存。
第二章:缓存策略与优化
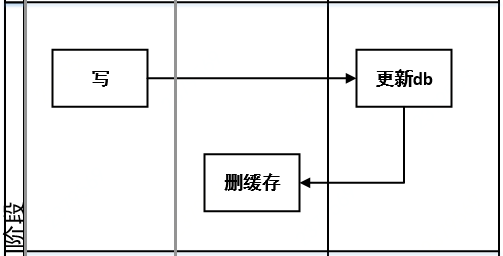
数据缓存并非简单地将所有数据存储在本地硬盘上,而是需要根据实际需求进行策略性地选择和优化。常见的缓存策略包括LRU(Least Recently Used)算法、LFU(Least Frequently Used)算法等。通过合理地选择合适的策略,并对缓存进行优化,可以提高数据的读取速度和效率。
第三章:数据一致性与失效处理
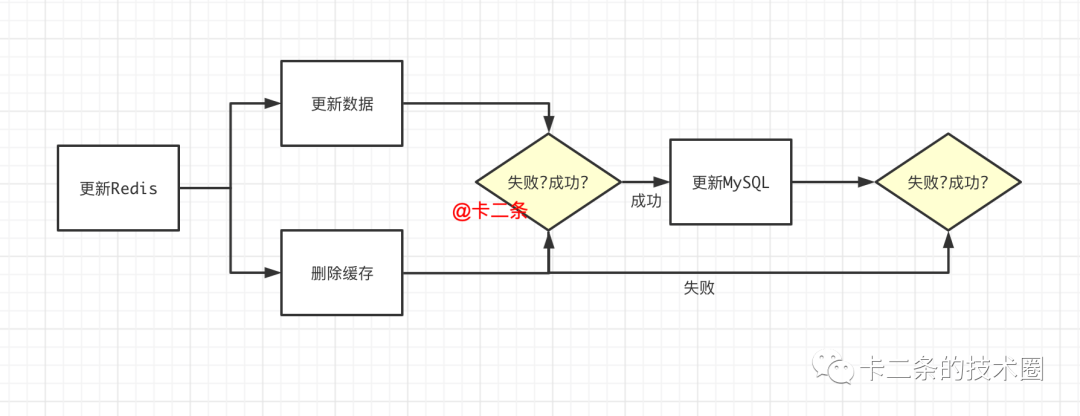
在进行数据缓存的过程中,我们还需要考虑数据一致性和失效处理的问题。由于数据的更新频率和源头的多样性,可能会出现数据不一致的情况。为了保证数据的准确性,我们需要定期对缓存中的数据进行验证和更新。